CNeRV: Content-adaptive Neural Representation for Visual Data BMVC 2022
- Hao Chen1 Matthew Gwilliam1, Bo He1, Ser-Nam Lim,
- Abhinav Shrivastava1
Abstract
Compression and reconstruction of visual data have been widely studied in the computer vision community, even before the popularization of deep learning. More recently, some have used deep learning to improve or refine existing pipelines, while others have proposed end-to-end approaches, including autoencoders and implicit neural representations, such as SIREN and NeRV. In this work, we propose Neural Visual Representation with Content-adaptive Embedding (CNeRV), which combines the generalizability of autoencoders with the simplicity and compactness of implicit representation. We introduce a novel content-adaptive embedding that is unified, concise, and internally (within-video) generalizable, that compliments a powerful decoder with a single-layer encoder. We match the performance of NeRV, a state-of-the-art implicit neural representation, on the reconstruction task for frames seen during training while far surpassing for frames that are skipped during training (unseen images). To achieve similar reconstruction quality on unseen images, NeRV needs 120x more time to overfit per-frame due to its lack of internal generalization. With the same latent code length and similar model size, CNeRV outperforms autoencoders on reconstruction of both seen and unseen images. We also show promising results for visual data compression. We provide code in the supplementary material.
CNeRV key takeaways
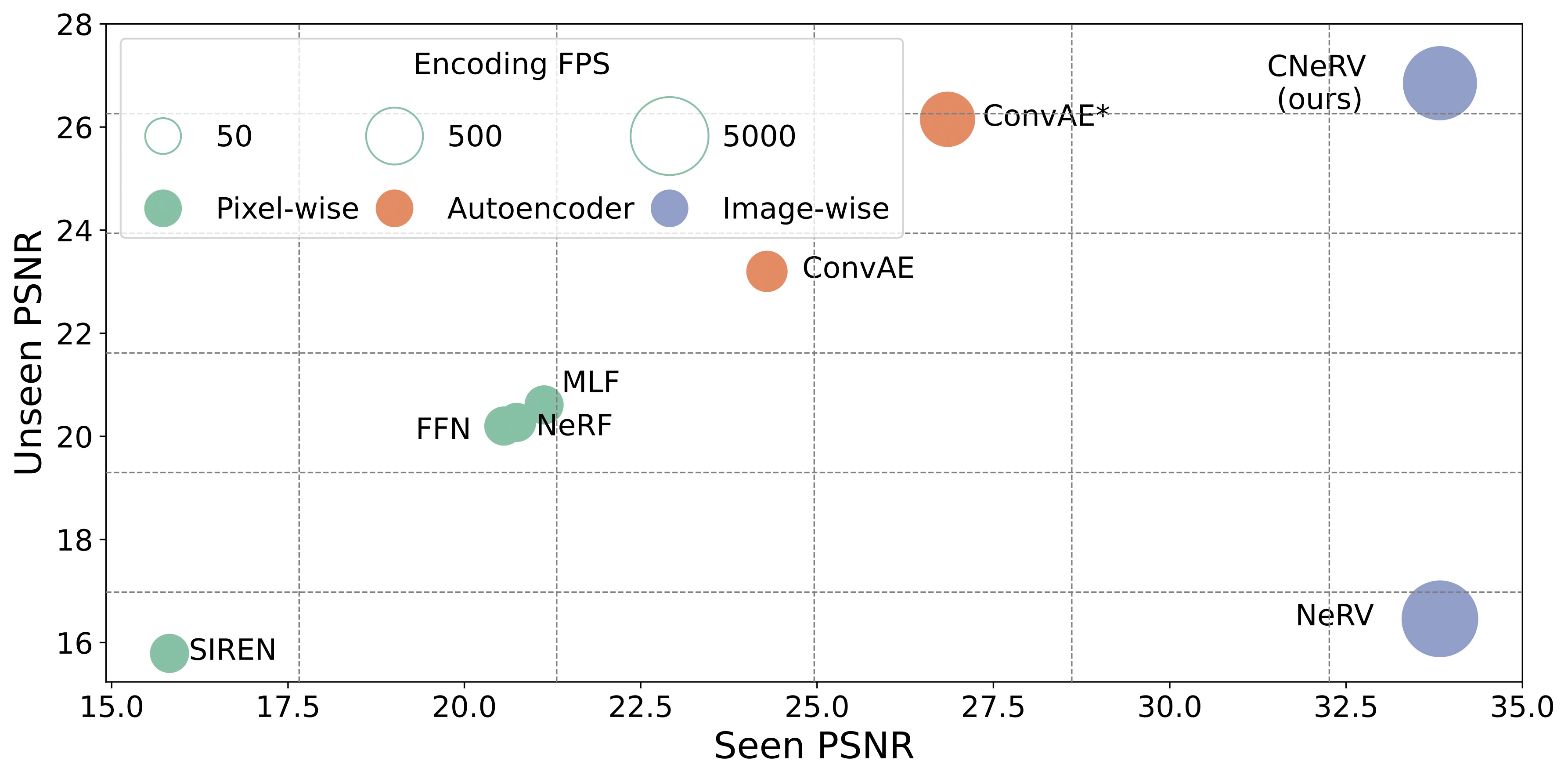
We propose a content-adpative embedding to introduce internal generalization for video neural representation. As shown in below image, CNeRV shows much better unseen PSNR and matches state-of-the-art seen PSNR, at fast encoding speed.
Method overview
CNeRV architecture
CNeRV visualizations
Unseen frames
Seen frames
Citation
The website template was borrowed from Ben Mildenhall.