NeRV: Neural Representations for Videos NeurIPS 2021
- Hao Chen1 Bo He1, Hanyu Wang1, Yixuan Ren1, Ser-Nam Lim2,
- Abhinav Shrivastava1
Abstract
We propose a novel neural representation for videos (NeRV) which encodes videos in neural networks. Unlike conventional representations that treat videos as frame sequences, we represent videos as neural networks taking frame index as input. Given a frame index, NeRV outputs the corresponding RGB image. Video encoding in NeRV is simply fitting a neural network to video frames and decoding process is a simple feedforward operation. As an image-wise implicit representation, NeRV output the whole image and shows great efficiency compared to pixel-wise implicit representation, improving the encoding speed by 25x to 70x, the decoding speed by 38x to 132x, while achieving better video quality. With such a representation, we can treat videos as neural networks, simplifying several video-related tasks. For example, conventional video compression methods are restricted by a long and complex pipeline, specifically designed for the task. In contrast, with NeRV, we can use any neural network compression method as a proxy for video compression, and achieve comparable performance to traditional frame-based video compression approaches (H.264, HEVC \etc). Besides compression, we demonstrate the generalization of NeRV for video denoising.
Method overview
We train a pixel-wise implicit representation to fit video frames.
Image-wise vs Pixel-wise


Video compression
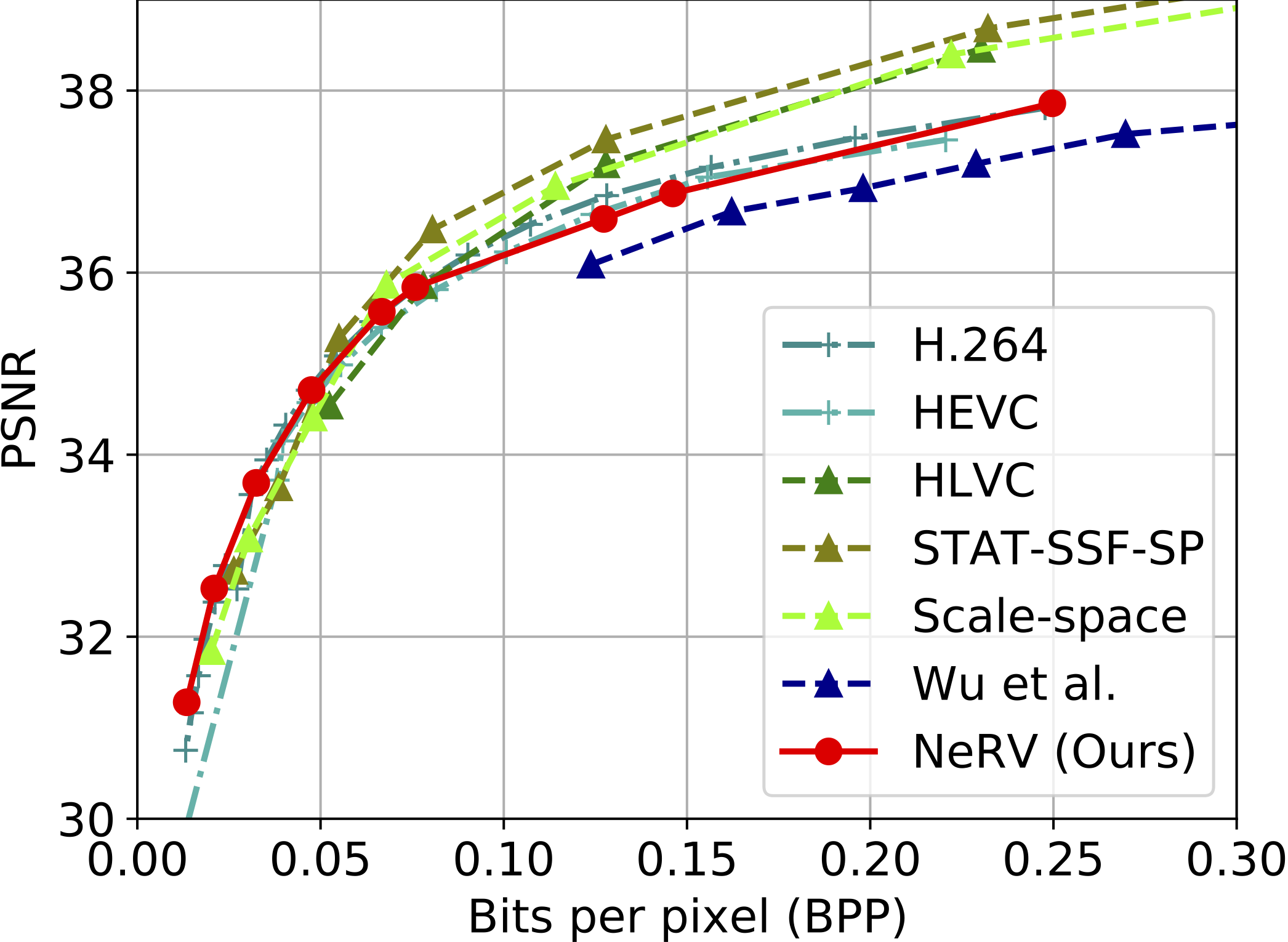
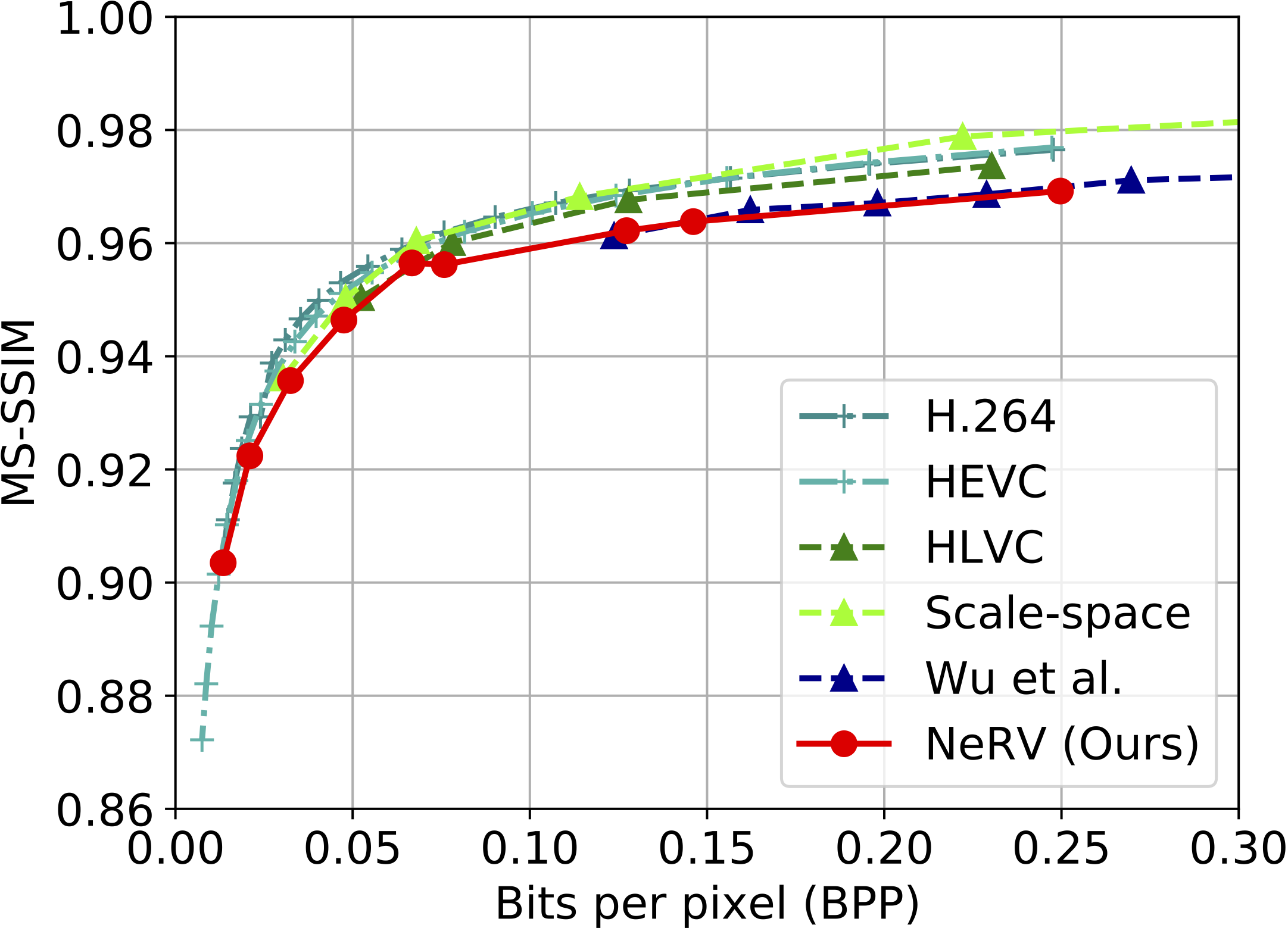
We convert video compression problem to model compression (model pruning, model quantiazation, and weight encoding etc.), and reach comparable bit-distortion performance with other methods.
Video denoising
NeRV achieves comparable or better denosing performance for most noises, without special denoising design, which comes totally from data regularization and architecture regularization.
Citation
The website template was borrowed from Ben Mildenhall.